![[rss feed 圖案]](/~ckhung/i/rss.png)
regexp 的資料繪圖應用實例
這篇講義的先修課程是: gnuplot 繪圖軟體的一點點, 及 字串樣版 regexp 的前四篇。
太陽系行星衛星質量-半徑比較圖
The Nine Planets
是一個很棒的教育網站, 介紹九大 (哦, 不, 剩下八大)
行星和太陽系內的其他物體。 從那裡取得 行星衛星基本資料表,
將它剪貼到一個純文字檔裡, 叫做 solar-system.txt 好了。 用 vim 編輯一下, 把它去頭去尾,
只剩下每列一顆星的基本資料, 和一些空列。 在 vim 裡面下
:%s/^/x / 在每列最前面加上一個 "x" 和空格。
然後把行星前面的 x 改成 0, ... 木星衛星前面的 x 改成 5,
土星衛星前面的 x 改成 6, ... 等等, 方便等一下用不同的顏色畫出。 vim
的 visual block mode 在這時非常好用, 建議請教一下身旁的 vim 高手。
再搜尋 Amalthea, 注意這顆衛星的質量 3.5e18 中間多了一個空格,
把它刪掉。 最後變成 這樣。
首先把我們有興趣的欄位抓出來: 它是誰的衛星? 名字叫什麼?
半徑幾公里? 質量幾公斤? 以下的指令, 請打在一列上, 中途不要換列。
perl -ne 'print "$1 $2 $3 $4\n" if /(\d+)\s+(\w+)\s+(\d+)\s+(\d\.\d+(e\d+)?)/' solar-system.txt > ~/s.txt 這麼長的指令, 很容易打錯。
建議從最簡單的 regexp 開始試起, 成功之後再逐步加長一點。 例如先打
perl -ne 'print "$1\n" if /^(\d) /' solar-system.txt >
x 抓出它的主星代號。
回到 gnuplot 視窗, 先試用一下 set label ... 指令和
set xrange ... 指令:
set label "good" at 3,1 center tc lt 1
set label "ok" at 1,3 center tc lt 2
plot sin(x)
plot x*x
set xrange [0:5]
set yrange [0:20]
replot
這些指令是什麼意思? 如果有興趣知道詳情, 請在 gnuplot 裡面下
help set label 閱讀手冊。 好了, 現在我們有三項任務:
(1) 找出 x 的範圍 (2) 找出 y 的範圍 (3) 產生一堆 set label
... 指令。
任務一很簡單: 在 shell 底下執行
sort -n -k 3 s.txt
就可以在排序結果的最上面看到最小值 (6),
在最下面看到最大值 (71492)。 這裡的 -n 表示將資料視為數字
(而非字串) 來排序; -k 3 表示從第三欄開始排序。
任務二: 用 sort -n -k 4 s.txt 可以嗎? 很可惜,
sort 看不懂科學記號。 又可以借助 regexp 了: perl -ne 'print
"$2 $1\n" if / ([\d\.]+)e(\d+)$/' s.txt | sort -n
發現最小值是 1.8e15 最大值是 1.9e27。
任務三: 現在要做一件奇怪的事情: 別人是用程式產生資料;
我們卻是用資料產生 (給 gnuplot 看的) 程式: perl -pe
's/(\S+)\s+(\S+)\s+(\S+)\s+(\S+)/set label $. "$2" at $3,$4 center
tc lt $1 /' s.txt > s.gpt 再用 less 或 vim 打開 y 來看看, 不錯吧?
堅持用滑鼠的人, 是無法理解命令列好處的。
 回到 gnuplot 視窗, 執行:
回到 gnuplot 視窗, 執行:
load "s.gpt"
set xrange [6:71492]
set yrange [1.8e15:1.9e27]
plot x*x*x*1e12*4*pi/3
 這裡的
這裡的 load "y" 把檔案 y 裡面的 gnuplot
指令逐一執行一次; 接下來兩句設定範圍;
最後一句畫出水球的質量-半徑圖。 (1km^3 * 1g/cm^3 = 10^12 kg
這是每立方公里的水的質量。) 嗯, 這圖看來醜醜的,
只有木星一顆遙遙領先; 其他星球都擠在左下角。 遇到這種狀況, 用
logscale 最合適了:
set logscale
replot
土星如果放在水裡, 會浮起來耶。
未修改完成...
畫地圖
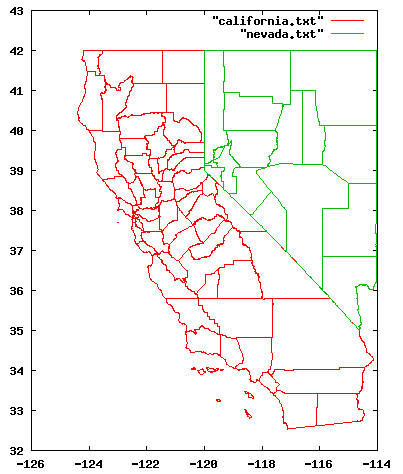
我們從美國 Census Bureau 的 TIGER/Line 網站 下載加州與內華達州諸郡的邊界座標檔, 稍微修改格式後, 用 gnuplot 畫出地圖。 沒辦法, 我也想以臺灣為例, 可是在網路上找不到類似的, 關於臺灣的資訊。 一樣, 請先跳出 gnuplot, 再重新進來一次, 以確定所有設定還原。
從上述網頁出發, 循著 "Cartographic Boundary Files" ==> "Download Boundary Files" ==> "County and County Equivalent Areas", 最後找到 加州諸郡的邊界座標檔。 注意我們要的是簡單的 ascii 格式, 不是 e00 格式。
解壓縮之後, 用 less
看一下。 按幾次空間棒, 可以往下看; 按 b 鍵可以倒退;
上下箭頭可以進距離移動; G 跳到檔案最後面; g 跳回檔案最前面;
^g 可以查詢現在正在檢視檔案的第幾列。
現在請按 /END 然後按 ENTER
鍵。 這裡的 / 表示搜尋; 搜尋到的字串會反白。 再按 n 搜尋下一個 END,
又按 ^g 再看一下目前位置。 輪流多按幾次 n
與 ^g。 最後按 G 跳到檔案最後面, 按 ? 及
ENTER 倒退搜尋剛剛的字串 (就是 END)
看一下加州總共有多少個郡?
再按 g 跳回最前面, 這次搜尋 " [0-9][0-9]* "
注意前後要有空格; 但不要把雙引號也敲進去。 再多按幾次 n
搜尋下一個。 是否看到每個郡開頭那列上面的 「郡代號」 都反白了? Q:
為什麼 [0-9] 要打兩次? 如果只打一次會怎樣?
回到我們的資料檔。 如果要把它改成 gnuplot 認得的資料格式, 必須刪除掉兩類的列:
- 每個郡的最前面, 有一個 「郡的整數代號」, 而且其後的座標不知道是什麼東東, 並不在邊界上, 應該整列刪除。
- 每個郡的最後面, 有一個 "END", 也應該刪除。
最後按 q 跳離 less。
我們先處理郡尾問題: 逐列檢查, 凡是遇到 "END", 就把它去掉:
perl -pe 's/END//' < co06_d00.dat | less 怎麼樣,
現在按 /END 搜尋不到 END 了吧? 倒是可以按
/^$ 搜尋空白列。 看不出任何東西反白嗎? 那是因為 ^
代表一列的開頭; $ 代表一列的結尾, 這兩個 regexp 的特殊符號都屬於
anchor 類字元。 就像錨一樣, anchor
類字元的功用只在將欲搜尋的字串釘在列首或列尾;
本身並不真的對應到任何一個字元。 這裡我們搜尋
"列首之後沒有任何字元, 馬上跟著列尾" 的字串, 就是在搜尋空白列。
雖然看不到反白, 還是可以輪流按幾次 n 與 ^g,
確認一下確實是在找空白列。
 順便一提, 這裡的 | 唸作 pipe 它就像水管一樣,
把前一個指令的輸出結果導給下一個指令接續處理。
這個看似不起眼的小東西, 其實就像是分子的化學鍵, 積木的齒,
英文的關係代名詞, 數學的小括弧, 影音設備的 AV 端子 (紅白黃三條線)
一樣, 是發揮 組合式學習
combinatorial explosion 爆發力的重要關鍵。 這是微軟不會告訴你的事;
這是絕地武士的入門第一階。
順便一提, 這裡的 | 唸作 pipe 它就像水管一樣,
把前一個指令的輸出結果導給下一個指令接續處理。
這個看似不起眼的小東西, 其實就像是分子的化學鍵, 積木的齒,
英文的關係代名詞, 數學的小括弧, 影音設備的 AV 端子 (紅白黃三條線)
一樣, 是發揮 組合式學習
combinatorial explosion 爆發力的重要關鍵。 這是微軟不會告訴你的事;
這是絕地武士的入門第一階。
接下來處理郡首問題。 我們將先前的結果過濾一下, 只留下
"含有兩串字串的列", 也就是要把郡首這種 "含有三串字串的列" 給刪掉:
perl -pe 's/END//' < co06_d00.dat | perl -ne 'print if
/^\s+\S+\s+\S+$/' | less 。 不過這樣做有點小問題:
我們把空白列也刪掉了。 沒關係, 先存檔: perl -pe 's/END//'
< co06_d00.dat | perl -ne 'print if /^\s+\S+\s+\S+$/' >
california.txt 並且從 gnuplot 裡面下 plot
"california.txt" 畫畫看。 如果你曾下過 set style data
lines 會發現多了一些沒有意義的線。
因為郡與郡之間的資料沒有分開, 所有資料被串成一條線了。
我們改一下過濾條件, 改成留下 "空列, 或含有兩串字串的列":
perl -pe 's/END//' < co06_d00.dat | perl -ne 'print if
/^(|\s+\S+\s+\S+)$/' | less 存檔再重畫一次看看吧。 這裡的
(...|...) 表示 "或"。 例如這個 regexp:
log(|s|ged|ging) 會搜尋 log, logs, logged, 或
logging。
以同樣的方式, 下載並處理 Nevada 州的地圖, 產生 nevada.txt。
然後進入 gnuplot 並下指令 : plot "california.txt",
"nevada.txt" 結果發現畫出來有點醜, 比例不太對。 在緯度 38
度附近, 經度每一度的距離, 大約是緯度每一度距離的 4/5,
或者更精確地說, 這個比例是 cos(38度)。 所以設定新的比例 set
size ratio 1/cos(38/180.0*pi) 重畫一遍。
倒不是我記得很清楚是誰比誰, 反正不是 cos(...) 就是 1/cos(...)
試試看就知道了啦。 如果你想知道比例究竟設成多少, 可以下 print
1/cos(38/180.0*pi) 把這個比值印出來。 注意: 在 gnuplot
的數學運算當中, 兩個整數相除, 會無條件捨去, 所以這裡的 180 寫成
180.0。
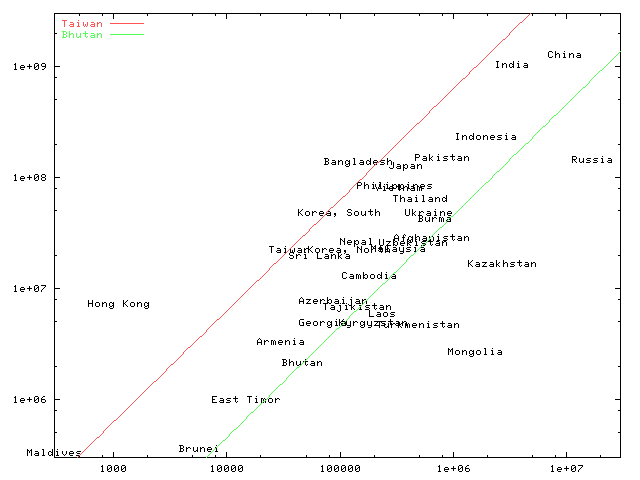
亞洲各國人口密度比較圖
[2010/10/10 註: 新版的資料格式已改變。 詳見 country comparison: population 及 country comparison: area。]
美國中情局網站有一個檔案可以下載, 叫做 CIA Fact Book 裡面有世界各國簡介, 對地理老師應該有一些用處。 解壓縮之後有一個 factbook/print 目錄。 我寫了一支小程式 ciafbxf 從那個目錄下的所有檔案裡面, 將一些最基本的資料擷取出來成為 all_countries.txt。 以下我們要從這個檔案裡面抓出亞洲各國的資訊, 以人口當做 x 軸, 土地面積當做 y 軸, 用 gnuplot 將各國名稱畫在座標平面上。
首先用 grep 過濾, 只取出亞洲國家資訊; 其次用 cut 過濾,
只取出國名, 人口, 與土地面積; 最後把這些資訊化成一堆 set
label ... 指令, 存成一個 gnuplot 命令稿。 注意:
最後一句話太長了, 所以用倒斜線 "\" 告訴 shell
我們的命令還沒有打完。 如果把整個命令打在同一列, 就不必打倒斜線。
語法請參考 regular expression 講義。
grep -i asia < all_countries.txt > tmp1.txt
cut -d : -f 2,5,8 < tmp1.txt > tmp2.txt
perl -ne 'print qq(set label "$1" at $2,$3 center\n) \
if /(.*):(\d+):(\d+)/' < tmp2.txt > asia_countries.gpt
如果沒有 grep 與 cut 可用, 就連前面兩句也可以用 perl 來做:
perl -ne 'print if /asia/i' < all_countries.txt > tmp1.txt
perl -ne 'print "$1:$2:$3\n" if \
/^.*?:(.*?):.*?:.*?:(.*?):.*?:.*?:(.*?):/' \
< tmp1.txt > tmp2.txt
如果是在 MS Windows 下, 最外層不能使用單引號, 必須使用雙引號。 把三句合併在一起寫成:
perl -ne "print qq(set label '$1' at $2,$3 center\n) if \
/^.*?:(.*?):.*?:.*?:(.*?):.*?:.*?:(.*?):/" all_countries.txt
(若在 unix 下, 則反而必須在 $ 前面加上 \ 以防 shell 解釋) 別擔心, 這些與 gnuplot 本身無關, 只是要順便強調 regexp 的用處。 不會 regexp 並不影響學習 gnuplot; 但是會了 regexp 之後, 你會發覺很多 gnuplot 看似派不上用場的情境, 其實也都可以發揮。
總之, 最後進入 gnuplot, 用 load 命令載入剛才產生的 gnuplot 命令稿 asia_countries.gpt, 並且以臺灣的人口密度與不丹的人口密度畫兩條線方便比較。 下 plot 畫圖的時候, 可以同時用 title 選項改變 「圖例」 所顯示的字串。 又, 因為 「圖例」 的內定位置是右上角, 與圖中資訊混雜, 所以我們將它移到空空的左上角去, 比較清爽。
load "asia_countries.gpt"
set logscale
set xrange [3e2:3e7]
set yrange [3e5:3e9]
set key top left
plot x*628.21 title "Taiwan", x*45.52 title "Bhutan"
臺灣地形圖
Gnuplot 可以畫 3-d 圖, 而且可以用滑鼠旋轉圖案改變視角。
先畫一個簡單的馬鞍面試試看: splot x*x-y*y
請用滑鼠旋轉圖案。 用這個東西學雙變數函數, 感覺愉快多了吧?
當然, 它不只可以畫 3-d 函數, 也可以畫 3-d 資料。 美國太空總署 JPL 實驗室的 Shuttle Radar Topography Mission 提供全球的地面高度資訊。 我下載北緯 23 度東經 121 度附近的資訊, 並寫了一個小程式 hgt2txt 將之轉換成 gnuplot 認得的純文字格式, 存成檔案 taiwan.txt:
./hgt2txt -s 100 > taiwan.txt
然後進入 gnuplot 畫圖:
splot "taiwan.txt" # 矮矮胖胖的, 不太像臺灣...
set xrange [0:60]; replot # 有點樣子。 如果著色呢?
set pm3d; replot # 還是太亂。 換個調色盤看看
set palette model HSV functions gray, 1, 1
replot #
set palette model HSV functions gray>0.01?gray*0.9:0, gray>0.01?1:0, 1
replot # 海面畫白色; 陸地由紅到紫
set view map; replot # 如果改畫平面圖呢?
set palette model XYZ functions gray**0.35, gray**0.5, gray**0.8
splot "taiwan.txt" lt 3 # 另外一個由黑到金的調色盤
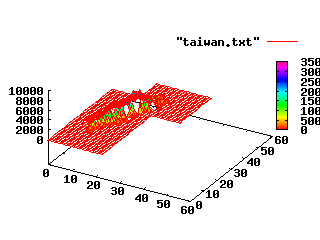
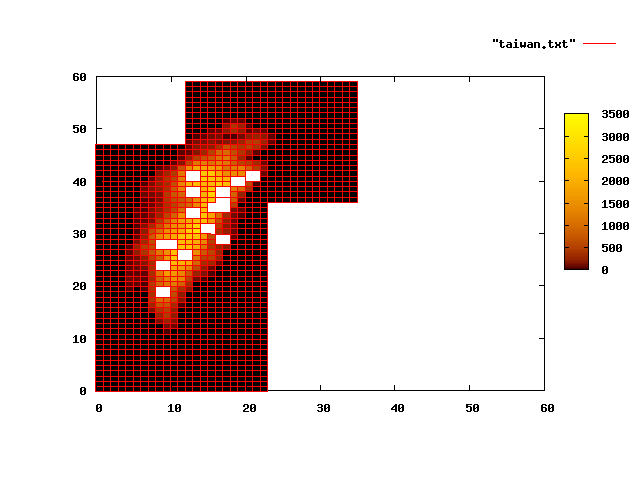
注意到資料檔 taiwan.txt 的格式:
- 每列一個數字, 代表一點的 z 值。
- 先是所有 y=0 的點, 隔著一個空列後是所有 y=0 的點, 再隔一個空列 ...
- 資訊不足處, 可以填 nan, 那麼 gnuplot 就會留白。 (Windows 版好像不行?)
gnuplot 也可以接受每列三個數字的檔案, 分別代表一點的 x,y,z 值。
假設資料固定每 m 列之後多一個空列, 這種樣版重複出現 n 次, 並且在
gnuplot 裡面設定 data style lines (或 linespoints),
那麼就可以畫出一個 m 乘 n 的 mesh (網狀結構)。 x-y
座標不必對齊成方格狀,; z 甚至不需要是 x-y 的函數
(曲面可以翻轉覆蓋在自己上面) 只要大致還算平滑, gnuplot
一樣可以處理, 像是這個簡單的範例: pyramid.dat (繪圖方式見檔案內註解)
因為地圖一般說來都比較不平滑,
所以上面臺灣地地形圖這個例子的效果不太好。 我們看一個較平滑的例子:
先在 shell 下執行 ./torus >
torus.dat 產生資料檔, 然後在 gnuplot 內下:
set hidden3d;
splot "torus.dat" with lines
[to-do: 到 這裡 下載 blender 做的 "星艦迷航記" 星艦模型, 用 blender 匯出成 dxf 格式, 再用 perl 轉成 gnuplot 可以讀的格式...]
- 本頁最新版網址: https://frdm.cyut.edu.tw/~ckhung/b/re/gnuplot.php; 您所看到的版本: August 08 2018 21:55:13.
- 作者: 朝陽科技大學 資訊管理系 洪朝貴
- 寶貝你我的地球, 請 減少列印, 多用背面, 丟棄時做垃圾分類。
- 本文件以 Creative Commons Attribution-ShareAlike License 或以 Free Document License 方式公開授權大眾自由複製/修改/散佈。